本文共 8259 字,大约阅读时间需要 27 分钟。
作者:韩
单位:燕山大学
目录
一、文本摘要(Text Summarization )任务
1.1 任务概述
文本摘要任务的起源最早能够追溯到 20 世纪 50 年代,美国 IBM 公司的 Luhn等人首次提出了使用计算机完成文本摘要任务, 即采用统计学方法来分析文本语法和语义信息的抽取式文本摘要算法。此项任务所要解决的问题就是文本信息过载,通过算法设计使计算机自动生成简短、完整的摘要,对各类文本进行一个“降维”处理,以此减轻人们的负担。
首先文本摘要任务按照输入的文本类型可分为单文档摘要和多文档摘要。单文档摘要任务是指从给定的一个文档中生成摘要,多文档摘要任务是指从一组主题相关的多个文档中生成摘要。其次,按照生成摘要的方法可分为抽取式摘要和生成式摘要。抽取式摘要从原文中抽取关键句,摘要全部来源于原文。生成式摘要则更加注重对原文的理解和重构,允许生成新的短语来组成摘要。按照有无监督数据可以分为有监督摘要和无监督摘要。
1.2 抽取式方法
抽取式方法通常被定义为序列标注任务,或者简单地二分类任务。即使用模型对输入本文中的每个句子进行评分,选出分数最高的前 n n n个句子作为摘要。比较经典的方法有Lead-3、TextRank等,这些方法虽然存在着很多缺点,但优点也很明显,如主题不易偏离、适应性广、速度快,且效果很好,如Lead-3方法在BERTSum中的测评结果,已经接近Transformer了。因此,就目前的形势而言,实际应用最广泛的还是抽取式文本摘要。
1.3 生成式方法
虽然抽取式摘要在实验研究和实际应用中都有着不错的表现,但其做法和我们理想的方案还是有很大区别。首先书写文摘的前提应该是模型对输入文本有着足够的理解,基于此模型对输入原文进行重构,其次在理想状态下我们希望所得的摘要能够对原文有着精确、完整的总结,这就要求摘要中不能只是简单地存在着原文的关键词,而是应该视情况对词汇进行转换,对原文所提事件进行全新的描述和总结,而这种能力在抽取式方法中是不可能实现的。
近些年随着神经网络技术的复苏以及预训练模型的发展,生成式方法也出现了质的改变,如2019年Yang Liu等人提出的、Jingqing Zhang等提出的在生成式文本摘要任务上都取得了相当突出的成绩。同时、、等预训练模型也为生成式方法的研究提供了新思路。
综合来看,生成式任务在设计上更加符合人脑的思维方式,并且更加灵活,模型上限更高,但目前来说,优点同时也缺点,更好的设计意味着更高的实现难度,更强的灵活性在目前的技术上也使得模型经常出现用词不准,内容离题等问题。但不可否定的是,生成式方法一直是文本摘要任务研究的核心,也是我们追求的最佳方法。在此笔者认为优秀的生成式模型需要做到以下三点:
- 正确掌握当前使用语言的语法结构
- 拥有突出的文本理解能力
- 拥有突出的语言组织能力
1.3 ROUGE评分标准
(Recall-Oriented Understudy for Gisting Evaluation)是在2004年由Chin-Yew Lin等人提出的一种自动摘要评价方法,现被广泛应用于DUC(Document Understanding Conference)的摘要评测任务中。
ROUGE基于摘要中n元词(n-gram)的共现信息来评价摘要,是一种面向n元词召回率的评价方法。ROUGE准则由一系列的评价方法组成,其中主要包括ROUGE-1、ROUGE-2、ROUGE-N、Rouge-L、Rouge-W、Rouge-S等。
ROUGE-N的定义为:
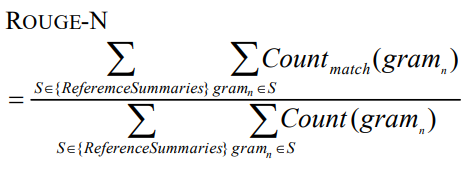
分母是n-gram的个数,分子是参考摘要和生成摘要共有的n-gram的个数。
Rouge-L的定义为:
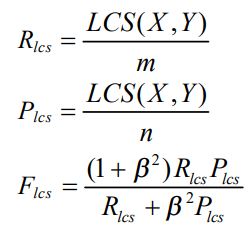
L即是LCS(longest common subsequence,最长公共子序列),其中 L C S ( X , Y ) LCS(X,Y) LCS(X,Y) 是 X X X和 Y Y Y最长公共子序列的长度, m m m, n n n分别表示参考摘要和生成摘要的长度,最后的 F l c s F_{lcs} Flcs也就是我们说的Rouge-L。在DUC中, β β β通常被设置为一个很大的数,所以实际上Rouge-L几乎只考虑了 R l c s R_{lcs} Rlcs,这也就表明了在Rouge测评中我们更加关注的是信息的召回率。
Rouge-W的定义为:

Rouge-W是针对Rouge-L存在问题的改进版,在Rouge论文中作者提出了一个假设
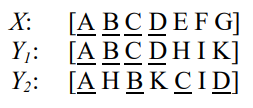
图中, X X X是参考摘要, Y 1 Y_1 Y1, Y 2 Y_2 Y2是两个待测评摘要,明显 Y 1 Y_1 Y1要优于 Y 2 Y_2 Y2,因为 Y 1 Y_1 Y1和参考摘要 X X X存在着多个匹配的片段,但是在计算Rouge-L时我们发现Rouge-L ( X , Y 1 ) (X,Y_1) (X,Y1)=Rouge-L ( X , Y 2 ) (X,Y_2) (X,Y2),针对这个问题论文作者提出了改进的方案—加权最长公共子序列(Weighted Longest Common Subsequence),即Rouge-W。
Rouge-S的定义为:

即使用了skip-grams,在参考摘要和生成摘要进行匹配时,可以“跳过”几个单词,也就是单词可以不连续出现,如skip-bigram,在产生grams时,允许最多跳过两个词。如“I want to eat meat”的 skip-bigrams 就是 “I want,I to,I eat,want to,want eat,want meat,to eat,to meat,eat meat”.
二、论文核心概述
2.1 模型设计思路
此篇论文在模型设计上仍然是依托于BERT预训练语言模型,主要针对的是BERT模型对于建立长距离依赖关系能力较差的问题。我们知道BERT模型的预训练任务是句子级的,同时在输入时存在最大序列长度的限制,因此导致BERT模型很难掌握文本中的长距离依赖关系,但作者通过对CNNDM数据集分析发现超过25%的核心句子出现在原文的前十个句子之后,并且对于新闻文档往往会出现多个核心人物和事件贯穿整个文档,所以长距离依赖关系学习能力差正是基于BERT建模所必须要解决的问题。因此,论文作者通过图结构中所蕴含的关系信息显示指导摘要生成,即使用RST Graph和Coreference Graph两种图结构构建了Graph Encoder层,进而加强模型对长距离依赖关系的掌握能力。实际上使用图结构改善摘要效果的做法并不少见,如2020年Wei Li等人提出的,也是基于图结构做出的改善,只不过针对的是多文档摘要任务。
2.2 模型优势分析
简单来说,以目前的技术进行文本摘要任务,抽取式方法不管是实际应用还是ROUGE评分都要强于生成式方法,但不能否认的是直接抽取原文句子然后组合成摘要的方法存在很多问题,如内容存在大量冗余信息、前后语句不通顺等,所以此篇论文的作者就想了一个折中的方法,整体上依然采用抽取式,但并不是直接抽取整个句子,而是将句子分成多个 Elementary Dis-course Unit(EDU),将EDU作为抽取的最小单元,也就是说此处模型设计者是要进行细粒度的抽取式摘要,这样设计抽取式任务,在保留方法优越性的同时将存在的问题也进行了完善。
三、DiscoBERT
3.1 RST Graph
判断模型对输入文本理解能力的一个关键点就是模型对句子间长距离依赖关系的掌握情况,论文中使用的(RST)是一种针对文本内局部关系的描述理论。在RST框架中,文本的关系结构可以用树的形式表示。整个文档可以分为连续、相邻且不重叠的文本范围,称为基本语篇单元即EDU。每个EDU都被标记为Nucleus或Satellite,可以简单理解为通过这种标记区分出核心句子和普通句子。被标记为Nucleus的节点通常位于中心位置,而Satellite节点则位于外围位置,并且在内容和语法依赖性方面不太重要。 需要注意的是作者虽然将文档切分为多个EDU,但每个EDU之间存在依存关系,代表着它们的修辞关系,并没有因切分导致每个EDU完全分隔开。在此基础上作者将EDU视为抽取式任务中内容选择的最小单位,希望模型选择文档中最简洁,最关键的概念,并且冗余度较低。作者提出的方法可以选择一个或几个细粒度的EDU,以使生成的摘要较少冗余。这是正是DiscoBERT模型的设计基础。
当抽取原文句子作为摘要时,常假设每个句子在语法上都是独立的。但是对于EDU,需要考虑一些限制以确保语法的正确性。因此RST图的构建需要经过两个步骤:文档分割和RST解析。
在分割阶段,作者使用基于BiLSTM CRF框架的神经语篇分割器,分段器在RST-DT测试集中获得94.3 F1分数,其中人类表现为98.3。在解析阶段,使用 shift-reduce语篇解析器提取关系并识别nuclearity。EDU之间的依赖性对于保证生成摘要的语法正确性至关重要。所选EDU的数量取决于参考摘要的平均长度、多个EDU间的依赖性以及已生成内容的长度。根据训练集调整所选EDU的最佳平均数量。RST Graph的构建不仅旨在为EDU之间提供本地段落级别的依赖关系,而且还提供远程文档级别的依赖关系。从第i个EDU到第j个EDU的相关性作为图的有向边,即 G R [ i ] [ j ] = 1 G_{R}[i][j]=1 GR[i][j]=1。RST Graph 的具体实现方法如下图所示:

在此,笔者认为论文中对图的描述是有问题的,在第四句中“…,and Satellite nodes including [2] and [4] are denoted …”此处[2]应该是[1],同样在第五句“The EDU [2] is the head if the…”这里的[2]也应该是[1]。
3.2 Coreference Graph
文本摘要(尤其是新闻摘要)通常会遇到“位置偏见”问题,即大部分关键信息在文档的开头就进行了描述,但是,在文档的中间或末尾仍然散布了大量的信息,摘要模型通常会忽略这些信息;此外,在长篇新闻文章中,整个文档中经常有多个核心人物和事件。但是,现有的神经模型在这种文档上建立长距离依赖关系的能力很差,尤其是当存在多个模棱两可的共指关系要解析时。
为了鼓励和指导模型学习输入文本中的长距离依赖关系,作者提出了基于EDU的共指图,其算法如下图所示:

作者首先使用方法来检测文章中的所有共指簇。对于每个共指集群,将所涉及的所有EDU连接起来。然后在所有共指集群中重复此过程,以创建最终的共指图。
3.3 DiscoBERT
DiscoBERT模型由Document Encoder和Graph Encoder组成。对于Document Encoder,首先使用BERT模型对整个文档进行编码。然后,使用self-attentive span extractor从对应的文本跨度中获取相应的EDU表示。Graph Encoder以Document Encoder的输出作为输入,并根据所构建的RST Graph或者Coreference Graph使用Graph Convolutional Network更新EDU的表示,最终用于预测oracle标签。
假设文档D总共分为n个EDU,即 D D D = { d 1 , d 2 , ⋅ ⋅ ⋅ , d n d_1, d_2,· · · , d_n d1,d2,⋅⋅⋅,dn},作者将抽取式方法定义为序列化标注任务,其中每个EDU由深度神经网络评分,并根据所有EDU的评分做出决策。 oracle标签是二进制标签序列,其中1代表被选择,0代表未被选择。作者将标签表示为 Y Y Y= { y 1 ∗ y_1^* y1∗, y 2 ∗ y_2^* y2∗, ··· , y n ∗ y_n^* yn∗}。在训练过程中,旨在预测给定文档 D D D所对应标签 Y Y Y的顺序。在推理过程中,需要进一步考虑语篇依赖性,以确保输出摘要的连贯性和语法正确性。DiscoBERT模型结构如下图所示:
3.3 Document Encoder
BERT模型的预训练任务是针对单个句子或句子对设计的,然而,在本次任务中我们需要BERT模型对整篇文档进行编码,因此我们需要进行一些调整,以便将BERT应用于文档编码。具体来说,我们分别在每个句子的开头和结尾插入和标记,并且为了更好的适应长文档,在模型设计时也将BERT可以使用的最大序列长度从512扩展到768。
标记化后的输入文档表示为 D D D = {
d 1 , d 2 , ⋅ ⋅ ⋅ , d n d_1, d_2,· · · , d_n d1,d2,⋅⋅⋅,dn},并且 d i d_i di = { w i 1 , w i 2 , ⋅ ⋅ ⋅ , w i l i w_{i1}, w_{i2},··· , w_{il_i} wi1,wi2,⋅⋅⋅,wili},其中 l i l_i li是每个EDU经过BPE分词编码后所包含的token数量。然后使用BERT模型对文档进行编码,经过BERT后模型文本序列长度没有发生变化: { h 11 B , ⋅ ⋅ ⋅ , h n l n B } = B E R T ( { w i 1 , ⋅ ⋅ ⋅ , w i l i } ) \{h_{11}^{B},··· ,h_{nl_n}^{B}\} = BERT(\{w_{i1}, ··· , w_{il_i}\}) { h11B,⋅⋅⋅,hnlnB}=BERT({ wi1,⋅⋅⋅,wili}) 文本在BERT编码器之后,作者采用了Lee等人提出的学习EDU表示形式。EDU表示计算如下所示: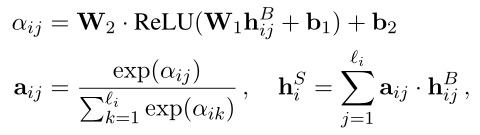
前文有提到 h i j B h_{ij}^{B} hijB的长度和输入文本相同, h i j B h_{ij}^{B} hijB就是每个单词在经过BERT模型后的得到的输出,也就是每个单词的编码表示,需要注意这个编码包含了全局信息,而不是单纯的字编码。每个EDU的分数计算方式为:
- 通过可学习参数 W W W和 b b b,计算每个单词的分数,也就是 α i j \alpha_{ij} αij。
- 使用softmax函数对结果进行归一化表示,也就是 a i j \mathrm{ a}_{ij} aij。
- 将 a i j a_{ij} aij作为单词权重,对整个句子进行加权求和,得到的 h i S h_{i}^{S} hiS就是每个EDU的分数。
这也就是论文中提到的 SpanExt操作,公式看着可能有点乱但实际上思路很简单,只不过是针对每个单词计算它的分数,也就是这个单词在EDU中的重要程度(注意,此处的计算和self-attn不一样,self-attn是计算每个单词和句中其他所有单词的关系,而此处只是计算了在这个句子中,每个单词的重要程度。在维度上前者是 1 ∗ s e q 1 ∗ seq 1∗seq_ l e n ∗ s e q len ∗ seq len∗seq_ l e n len len,后者是 1 ∗ s e q 1 ∗ seq 1∗seq_ l e n len len),然后对整个句子进行加权求和,因为单词编码是BERT对全文的输出,因此不是一个EDU的计算,多个EDU间存在着联系,也就成为了最终计算EDU分数的基础。最终在经过SpanExt操作之后,整个文档被表示为:
h S = { h 1 S , . . . , h n S } h_{}^{S} = \{h_1^S, ..., h_n^S\} hS={ h1S,...,hnS}3.4 Graph Encoder
给定构造的图形 G G G = ( υ \upsilon υ, ε \varepsilon ε),节点 υ \upsilon υ对应于文档中的EDU,而边 ε \varepsilon ε对应于RST话语关系或共指关系。然后,作者使用图卷积网络更新所有EDU的表示形式,以捕获BERT遗漏的长距离依赖关系。为了使体系结构设计模块化,作者提出了一个语篇图编码器(DGE)层。实验中堆叠了多个DGE层,第 k k k个DGE层的设计如下:

其中LN(.)表示归一化层, N i \mathcal{ N}_i Ni表示第 i i i个EDU节点的邻节点,即邻域运算。 h i ( k + 1 ) h_i^{(k+1)} hi(k+1)是第 k k k个DGE层的第 i i i个EDU节点的输出,在第一个DGE层中 h ( 1 ) h_{}^{(1)} h(1) = h S h_{}^{S} hS即Document Encoder的输出作为Graph Encoder的输入。在经过K层的图传播后,我们得到了最终的EDU表示: h G h_{}^{G} hG = h ( k + 1 ) h_{}^{(k+1)} h(k+1)。同时对于不同的图,不共享DGE的参数。如果同时使用两个图(RST Graph和Coreference Graph),则它们的输出是串联在一起的:
h G = R e L U ( W 6 [ h C G ; h R G ] + b 6 ) ) h_{}^{G} = ReLU(W_6[h_{C}^{G} ; h_{R}^{G}] + b_6)) hG=ReLU(W6[hCG;hRG]+b6))3.5 Training & Inference
在训练过程中 h G h_{}^{G} hG被用于预测oracle标签:
y ^ i = σ ( W 7 h i G + b 7 ) \hat y_i = \sigma(W_7h_{i}^{G} + b_7) y^i=σ(W7hiG+b7) 该模型的训练损失函数是二进制交叉熵损失: L = − ∑ i = 1 n ( y i ∗ l o g ( y ^ i ∗ ) + ( 1 − y i ∗ ) l o g ( 1 − y ^ i ) ) \mathcal{ L} = - \sum_{i=1}^{n}(y_{i}^{*}log(\hat y_{i}^{*}) + (1-y_{i}^{*})log(1-\hat y_{i})) L=−i=1∑n(yi∗log(y^i∗)+(1−yi∗)log(1−y^i)) 在推理的过程中,给定一个输入文档,在获得所有EDU的预测概率后,进行降序排列,并相应地选择EDU。EDU之间的依赖性在预测中也得到强制执行,以确保生成的摘要的语法正确性。四、实验分析
在实验部分,作者选择了两个比较权威的公共数据集CNN/DM和NYT,实验数据如下图所示:
CNN/DM

NYT

语法正确性检查

人类评估结果

五、总结
DiscoBERT模型设计的核心是将文档切分为多个EDU,利用图结构指导摘要生成并且解决长距离依赖问题。模型设计时为了能够方便构建长距离依赖关系,将BERT支持的最大输入长度扩充到了768,并且对整个文档进行编码,虽然后面是对每个EDU进行操作,但是并没有完全将文档信息割裂开。但是需要注意BERT模型本身具有建立长距离依赖关系的能力,只是相对较差。因此后面添加基于图的编码结构,只是加强了模型建立文档长距离依赖关系的能力,而不是让BERT模型拥有建立长距离依赖的能力。对于使用图结构增强摘要能力笔者认为,可以简单地理解成BERT模型本身是一个学生,他有学习能力,但是光靠他自己学习,所能学到的知识和能力是有限的,因此需要一个老师在他学习的过程中进行指导,那么在这篇论文中作者选择的老师就是Coref Graph和RST Graph,通过这两种图结构对文本进行分析,然后对模型进行显示指导或者说是强制性的干预,以加强学习效果。
转载地址:http://eqmgi.baihongyu.com/